(以上是“墨子沙龙 X 2023年科技节”的报告回放。)
内容概要:
ChatGPT出现之后,人们对于人工智能的关注度达到了前所未有的高度。而提到ChatGPT,就不得不提到一个词——人工智能大语言模型。我们之所以感受到ChatGPT惊人的智能,就缘于大语言模型的深度学习系统,特别是GPT3出现之后,大语言模型在多方面展现出了越来越强大的能力。
纵观GDP及其它大语言模型近年来的发展,发展速度之快、模型的参数量之大,令很多专家都惊叹不已。尤其是大语言模型在若干关键性能指标上的涌现能力,展现了在某个节点上,大语言模型将会实现从量变到质变的过程。而这个涌现的节点,就是人工智能领域,特别是大语言模型研究亟待突破的关键点。
ChatGPT的诞生是一个突破,问世近半年,已经掀起了人工智能领域的热潮。通过指令监督学习、打分模型学习、强化学习优化三个步骤的全面提升,ChatGPT实现了性能的飞跃。
根据行业调研报告,ChatGPT仅用了两个月,就实现了活跃用户的指数级别增长。而紧随其后的GPT4更是表现出更加强大的知识理解能力和推理能力。相应的,业界也亟需思考如何科学、全面地评价大语言模型的优劣。
大语言模型的进步正在突破越来越多的应用场景,将会在工业界驱动越来越多的b端或c端升级。而面对大语言模型的明天,我们的教育需要做什么样的升级和改变,则是一个需要社会、学校、家长、教师共同参与的话题。人工智能时代,我们到底需要培养学生的哪些能力?学校应该如何引导学生更加规范、合理的使用人工智能工具?而对于人工智能领域从业者来说,也需要思考,如何让大语言模型具备更全面化、工具化的能力,让人工智能更加可信和安全,可以伴随孩子共同学习和成长。
从研究者的角度,目前的大语言模型基本还是软件层面,而以大模型为基础的未来的智能系统,必定需要智能系统和物理世界可以进行多模态的理解、推理和交互,大模型需要与物理世界的知识进行对齐,才能让人工智能在虚拟世界中学习到的知识,能够用来解决实际问题。
今天,我想从“大语言模型的教育”和“大语言模型的产业”两个维度来分享大语言模型的今天和明天。
什么是大语言模型?
其实,大语言模型分很多种,如今大家比较关注的可能是这样一类——我们可以去和它进行一定方式的通信,比如输入一个提示词,一句话,或者是一段对话,大语言模型凭借深度学习系统,根据用户输入的文本,去预测下一个词是什么,这个过程周而复始,最终完成一个更长序列的文本的生成,就像ChatGPT现在表现的这样。
自从GPT-3推出以后,大语言模型体现出了一些非常强大的能力。其中,一个非常重要的能力就是所谓的“上下文学习能力”,或者叫“语境学习能力”。
那么,“上下文学习能力”是什么意思呢?举个例子,如果我们想对它解释一个任务——翻译,我们就可以告诉它一些把英语翻译成法语或者是中文的例子,这时候,不同于以往的神经网络或者深度学习的人工智能系统,现在的大语言模型在面对新的任务时,非常强调泛化的学习能力,我们只需要告诉大语言模型几个简单的翻译的例子,其实就定义了这个新的任务,再用几个简单的例子去告诉大语言模型该怎么做,它就可以对你提出的新的单词给出正确的翻译。
所以,所谓的“上下文学习能力”,其实就是说,大语言模型本身的泛化学习能力是非常强的,我们可能只需要告诉它若干的少数几个例子,它就可以学习并且完成一个新的任务。大语言模型近三四年的发展日新月异,从2018年的GPT系列到2020年的GPT-3系列,再到如今的GPT-4,我们可以发现,这个历程的发展速度极其之快,而且很多语言模型的参数量会越来越大。
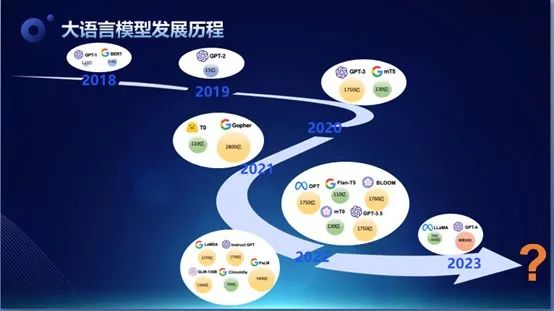
图一 大语言模型发展历程
举个最简单的例子。从GPT-1到GPT-2,短短的一年时间,参数量就从1亿扩大到15亿,然后再到GPT-3,参数量是1,750亿,参数量的飞跃为各方面的能力带来了新的提升,比如上下文学习能力,涌现能力等。这些是参数量,也就是神经网络深度学习系统的复杂程度决定的。虽然不知道GPT-4的训练细节和参数,但是我们相信它和同时期的其它系统,应该都具有很大的参数量规模。
还有第二个能力也是非常重要的,就是“大模型的涌现能力”。图二来自于实验结果,图中的每一张子图,都代表了一种大模型在某一个任务上的性能表现,比如说准确率等,数值越大,可能性能越好。
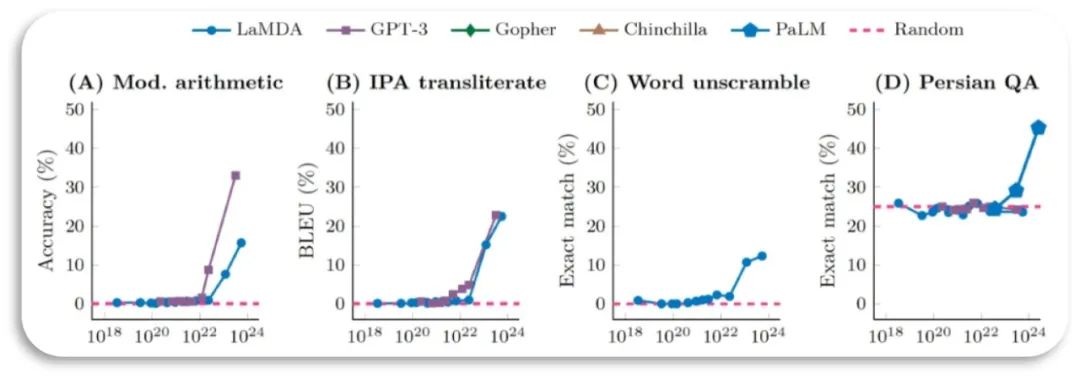
图二 大语言模型的涌现能力
图中的横轴代表的是关于模型规模的一些指标,当然,模型的规模,不仅仅体现在参数量的大小,也与其它因素有关。不过无论如何,横轴代表参数量或者规模,通过这张图,我们知道了,随着模型的参数量越来越大,或者说整个模型的规模越来越复杂,它会在超过某一个临界点的时候,实现一些能力的突变。体现在纵轴,可以看出,性能会有一个快速的飞升,这种能力就被定义成所谓的“大语言模型的涌现能力”。
其实“涌现能力”这个词并不是人工智能领域特有的,这个词早在几十年前,就被一名获得过诺贝尔物理学奖的科学家提到了。其实,用咱们中国的古代哲学来理解,涌现能力也就是量变到质变的能力。
迄今为止,我觉得它对于整个人工智能领域,特别是大模型方向的研究来说,依然是一个亟待去突破的能力。2022年底距今不过半年,ChatGPT的诞生完成了这样的突破,也使整个人工智能领域掀起了一个新的进步狂潮。
其实,ChatGPT在做的事情主要分三个步骤:第一个步骤,如果已经有了一个训练好的大模型的基座模型,它可以进行“指令的监督学习”,指令的监督学习其实并不难,需要一些合理的人工标注或者一些合理的监督数据集;然后去做第二步——一个自动的打分模型,为了训练这样的打分模型,现在已经有各种各样更加自动化的方式;第三个步骤就是强化学习优化策略,可以帮助整个系统实现进一步的性能提升。所以说,ChatGPT这三个步骤,每一个步骤都实现了非常有趣的性能提升,三个步骤叠加在一起,最终带来了整个系统的飞跃。
大语言模型的现状
我想从产业的角度来提一些有意思的新现象。
根据最新的行业调研报告,2023年1月,ChatGPT的月活跃用户已经达到一个亿,这意味着,1月份平均每天有超过1,300万名独立的访问者使用ChatGPT,这是去年12月份刚刚发布时候的两倍多,它其实已经成为史上用户增长最快的消费者应用程序。ChatGPT只用了两个月,就实现了用户的指数增长,相比之下,我们熟悉的很多非常强大的消费者端应用,都需要花更长的时间来实现。
ChatGPT推出之后,GPT-4——也就是GPT第四代大语言模型,也很快就推出了,相比之前的几代大语言模型,GPT-4拥有更强大的推理能力。
举一个具体的例子,如果需要去设置一个会议的时间,满足很多与会者共同的时间要求,这是一个非常常用的应用。GPT-4或者其它同等量级的大模型,已经具备完成这样稍微复杂的推理任务的能力。那么,对于更复杂的一些推理任务会怎么样?这里有一个表格,展示的是GPT-4为代表的这一代大语言模型,在各种人类考试上表现得非常优秀。其中,最高的这些绿色代表的都是GPT-4模型的性能。

图三 GPT-4 在各种人类考试上表现卓越
举例说明,纵轴的90%,意味着该模型超过理想中90%的人类的考试水平。图中很多绿色纵轴的出现,说明在很多人类的考试水平上,GPT-4的能力超过大部分人类的平均表现水平。
值得注意的是,这既体现了GPT-4具有非常强大的知识理解能力、甚至推理的能力,同时,也给我们的教育带来新的思考。
在开始讲述大语言模型如何影响我们的产业之前,我想简单讨论一下,我们怎么样去评测大语言模型的能力,这一点现在变得愈加关键。正如我们刚才看到的,很多人类考试上,大语言模型已经表现得非常好了,这个时候,我们需要更加全面的评价体系。举一个最简单的例子,我们知道,中国语言博大精深,同一个表达在不同场景下,意义会有所区别。我们告诉大语言模型一段具有言外之意的对话,看大模型能不能理解这个言外之意,事实上,在某些例子上,大语言模型的表现能力确实是非常不错的。
大语言模型的突破带来了各种各样的应用场景的突破,从工业界产品应用的角度来看,几乎可以为现在所有的b端或者c端的应用升级带来新的驱动。比如,通过积极开展针对b端企业用户的产品升级,可以和儿童们一起创作故事、小说,可以在智能车舱内实现对话的升级等。
大语言模型的明天
下面,我要畅想一下大语言模型的明天以及面对大语言模型的明天,教育应该如何转型和升级。
大语言模型对教育会有哪些影响?会改变教育的内容和方式,更加需要培养学生的综合素质,会推动教育模式的一些改革,也会影响教师本身的角色。这些都需要全方位的思考。教育机构需要积极适应这种现实,更好地满足学生和社会的要求。
我本人在香港中文大学任教,对于本科生,我会在教课的过程中,告诉他们ChatGPT的强大,同时我也会思考两个问题。第一,人工智能时代我们到底需要培养学生的哪些能力?我想,对于以前的填鸭式的教育,某种程度上需要我们重新思考、改变。第二,人工智能时代,学校应该如何规范学生合理地使用智能工具?这可能涉及到学校应该和教师、学生如何通过互动来解决这个问题。
从大模型的角度来说,我认为有两点是非常重要的。
第一点是大模型本身一定会具备更全面的工具化的能力,这一点其实需要我们重新衡量大模型的能力,虽然我们希望大模型能够完成各种复杂的任务,但是我们并不一定希望或者迫切的需要大模型本身足以解决所有的任务,因为我们人可以通过学习或者使用工具来解决新的任务。当然,如果有一天,我们教会大模型,自己教会自己通过使用新的工具去解决新的任务,这也是一个非常有意思的科研问题。
第二点就是可信和安全的人工智能,这对教育行业是非常重要的。我们的希望在未来,儿童能够快乐地在电脑上和人工智能一起互相学习,这样的情景是我们非常期待的。
最后,从研究角度来说,结合我自己所带领的香港中文大学语言和视觉实验室,我想聊聊我们目前关注的几个比较前沿的研究方向,第一个就是与物理世界的交互。大语言模型本身现在还是存在于软件层面,但是以大模型为基础的未来的智能系统,一定会和物理世界存在更多的交互,而这种交互一定是多种模态的,比如需要视觉信号、语言信号、声音信号等。
GPT现在已经有了一定的关于语言和图像联合理解的能力,但是目前来看还远远不够。因为大语言模型更加需要的是一个三维视觉场景内的感知和推理。如果大语言模型只是针对输入的图像和视频,那么其实和人类的通用智能并不能完全走在一起,所以我们更加关注的是,将来的机器人或者说真正的通用智能系统,能够从三维的感知世界中学到一些新的知识,以及如何把这件事情和人类的一些能力进行更好的对齐。大模型需要和物理世界进行更多知识的对齐,甚至是交互。机器人应当利用虚拟世界中大模型得到的一些先验知识和学到的新知识,去解决真正的实际场景中一些实际的新问题。
王历伟,教授,博士毕业于美国伊利诺伊大学香槟分校(UIUC)计算机科学系,目前担任香港中文大学计算机科学与工程学系助理教授,博士生导师。王历伟教授在人工智能语言和视觉多模态领域有着至少十年专注的研究积累。他所建立和带领的香港中文大学人工智能语言和视觉实验室(LaVi Lab)专注于语言和多模态大模型的前沿研究。王历伟教授从0到1带领商汤研究院自然语言处理团队,打造商汤自研中文语言大模型“商量“(SenseChat),并致力于带领团队探索突破大模型研究和应用的技术边界。
同时,王历伟教授担任过若干人工智能顶级学术会议区域主席(如CVPR等)和人工智能顶级学术期刊 IJCV(CCF-A类)编委。在他加入香港中文大学任教之前,拥有丰富的工业界科研经验,曾在腾讯西雅图人工智能实验室担任高级研究员,负责多个语言和多模态研究项目。

更多科技节报告回放,请点击:


